Xingchen Zeng 
I am a third-year PhD candidate in Data Science and Analytics at the Hong Kong University of Science and Technology (Guangzhou), supervised by Prof. Wei Zeng and Prof. Wei Wang. I received my Bachelor's degree from Central South University with honors, supervised by Prof. Jiazhi Xia.
My research focuses on empowering Large Language Models with human-like comprehension and creation of structured visual content, unlocking new capabilities in AI-driven design, reasoning, and communication.
I'm currently working as a research intern at Accio, Alibaba Group.
Email: xingchen.zeng@outlook.com
Links: [Google Scholar]
[GitHub]
[Curriculum Vitae]
News
- Highlight DaVinci is accepted by ICLR 2026.
- Highlight Check the LLM × Visualization paper list. Feel free to open an issue or pull request to add papers you appreciate.
Papers
Under Review
- Xingchen Zeng, Yuanbang Liu, Jianing Hao, Wei Zeng. Chart-G1: Visually Grounded Chart Reasoning by Rewarding Multimodal Large Language Models. Under Review. Slides
Published
-
Xingchen Zeng, Zhewei Su, Hengming Zhang, Juyong Jiang, Jiazhi Xia, Wei Zeng.
DaVinci: Reinforcing Visual-Structural Syntax in MLLMs for
Generalized Scientific Diagram Parsing.
The Fourteenth International Conference on Learning Representations, 2026.
Paper
Code
Abstract
▼
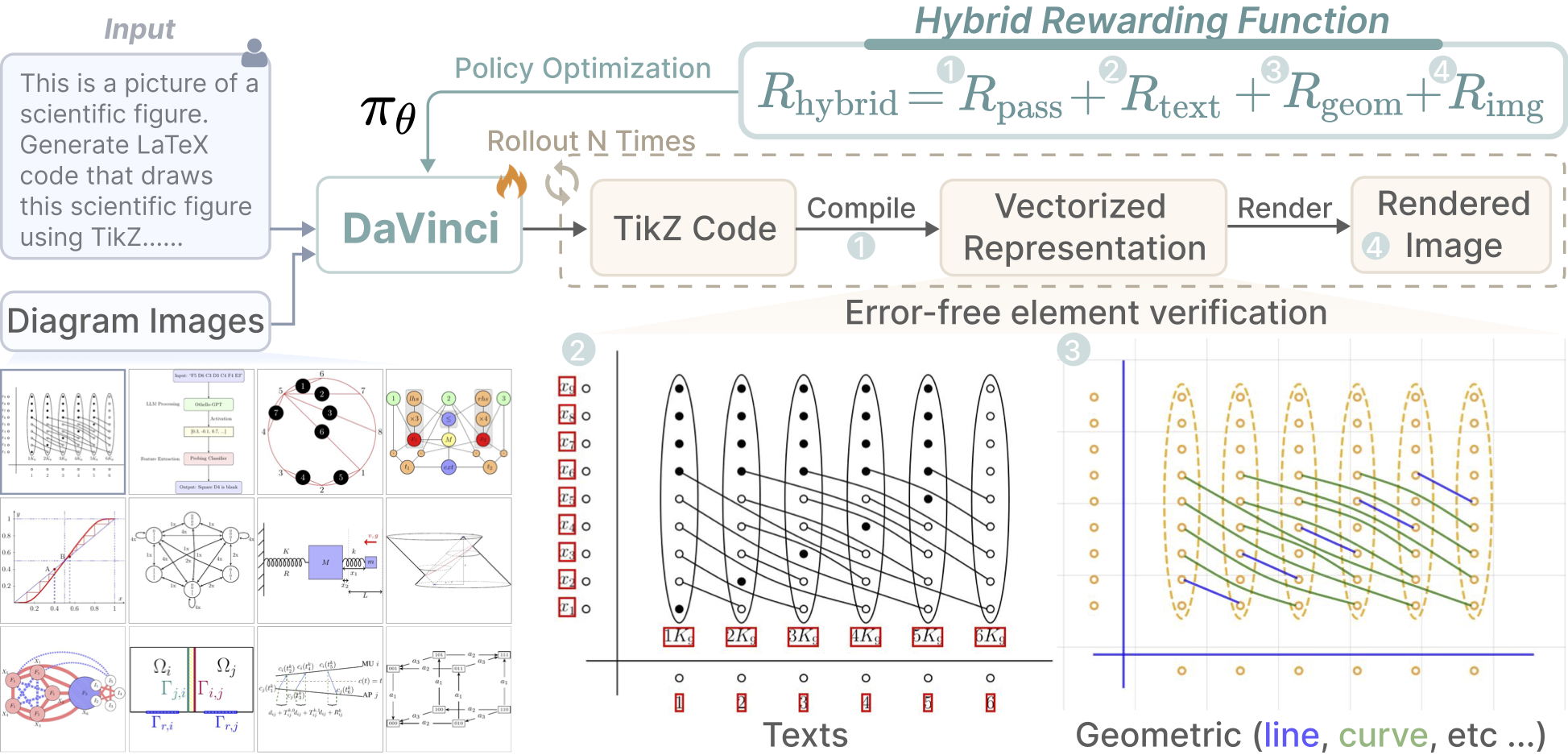 Parsing raster-based scientific diagrams into structured representations is critical for editability and reusability. However, existing multimodal LLMs (MLLMs) struggle with the diverse visual primitives, complex structural layouts, and strict syntax involved. To address this, we introduce DaVinci, a novel MLLM that learns diagram parsing based on a two-stage framework—supervised learning of visual primitives followed by reinforcement learning of their structural relationships. Our model learns visual-structural syntax through supervised training on TikZ30K, a newly curated dataset of high-quality diagram-TikZ code pairs that features abundant visual primitives and structurally optimized drawing sequences. We further refine the model via reinforcement learning, guided by a hybrid reward function that jointly optimizes for visual fidelity, structural consistency, and code correctness. Extensive experiments show that DaVinci significantly outperforms existing open-source MLLMs and surpasses leading proprietary models like GPT-5 and Claude-Sonnet-4.
Parsing raster-based scientific diagrams into structured representations is critical for editability and reusability. However, existing multimodal LLMs (MLLMs) struggle with the diverse visual primitives, complex structural layouts, and strict syntax involved. To address this, we introduce DaVinci, a novel MLLM that learns diagram parsing based on a two-stage framework—supervised learning of visual primitives followed by reinforcement learning of their structural relationships. Our model learns visual-structural syntax through supervised training on TikZ30K, a newly curated dataset of high-quality diagram-TikZ code pairs that features abundant visual primitives and structurally optimized drawing sequences. We further refine the model via reinforcement learning, guided by a hybrid reward function that jointly optimizes for visual fidelity, structural consistency, and code correctness. Extensive experiments show that DaVinci significantly outperforms existing open-source MLLMs and surpasses leading proprietary models like GPT-5 and Claude-Sonnet-4. -
Xingchen Zeng, Haichuan Lin, Yilin Ye, Wei Zeng.
Advancing Multimodal Large Language Models in Chart Question
Answering with Visualization-Referenced Instruction Tuning.
IEEE Transactions on Visualization and Computer Graphics (Proc. IEEE VIS 2024), 2024.
Paper
Slides
Code
Abstract
▼
Emerging multimodal large language models (MLLMs) exhibit great potential for chart question answering (CQA). Recent efforts primarily focus on scaling up training datasets (i.e., charts, data tables, and question-answer (QA) pairs) through data collection and synthesis. However, our empirical study on existing MLLMs and CQA datasets reveals notable gaps. First, current data collection and synthesis focus on data volume and lack consideration of fine-grained visual encodings and QA tasks, resulting in unbalanced data distribution divergent from practical CQA scenarios. Second, existing work follows the training recipe of the base MLLMs initially designed for natural images, under-exploring the adaptation to unique chart characteristics, such as rich text elements. To fill the gap, we propose a visualization-referenced instruction tuning approach to guide the training dataset enhancement and model development. Specifically, we propose a novel data engine to effectively filter diverse and high-quality data from existing datasets and subsequently refine and augment the data using LLM-based generation techniques to better align with practical QA tasks and visual encodings. Then, to facilitate the adaptation to chart characteristics, we utilize the enriched data to train an MLLM by unfreezing the vision encoder and incorporating a mixture-of-resolution adaptation strategy for enhanced fine-grained recognition. Experimental results validate the effectiveness of our approach. Even with fewer training examples, our model consistently outperforms state-of-the-art CQA models on established benchmarks. We also contribute a dataset split as a benchmark for future research.
- Xingchen Zeng, Ziyao Gao, Yilin Ye, Wei Zeng. IntentTuner: An Interactive Framework for Integrating Human Intentions in Fine-tuning Text-to-Image Generative Models. Proceedings of the CHI Conference on Human Factors in Computing Systems, 2024. Paper
- Xingchen Zeng, Haowen Zhou, Zhicong Li, Chenqi Zhang, Juncong Lin, Jiazhi Xia, Yanyi Yang, Xiaoyan Kui. iHELP: interactive hierarchical linear projections for interpreting non-linear projections. Journal of Visualization (Proc. ChinaVis 2022), 26(3): 631-648, 2023. Paper
- Zhicong Li, Lingjie Jiang, Yulan Hu, Xingchen Zeng, Yixia Li, Xiangwen Zhang, Guanhua Chen, Zheng Pan, Xin Li, Yong Liu. No More Stale Feedback: Co-Evolving Critics for Open-World Agent Learning. ACL 2026 Paper
- Yilin Ye, Junchao Huang, Xingchen Zeng, Jiazhi Xia, Wei Zeng. AKRMap: Adaptive Kernel Regression for Trustworthy Visualization of Cross-Modal Embeddings. Proceedings of the Forty-Second International Conference on Machine Learning, 2025. Paper Code
- Yihan Hou, Xingchen Zeng, Yusong Wang, Manling Yang, Xiaojiao Chen, Wei Zeng. GenColor: Generative Color-Concept Association in Visual Design. Proceedings of the CHI Conference on Human Factors in Computing Systems, 2025. Paper Code
- Yilin Ye, Shishi Xiao, Xingchen Zeng, Wei Zeng. ModalChorus: Visual Probing and Alignment of Multi-modal Embeddings via Modal Fusion Map. IEEE Transactions on Visualization and Computer Graphics (Proc. IEEE VIS 2024), 2024. Paper Code